Carolyn Newmark on Creating Seamless AI Workflows
The release of OpenAI’s GPT-5 is a huge moment for generative AI, pushing the boundaries of what’s possible. For engineering teams, this is a call to action. But as our product leader, Carolyn Newmark, knows all too well, leveraging a new frontier model isn't simple. Without a unified platform, you're often stuck with infrastructure headaches, security concerns, and complex integrations. These hurdles can delay your projects by weeks or even months, turning an exciting opportunity into a frustrating slog.
Cake is built to solve this. We provide a managed, open-source platform that enables teams to deploy solutions that leverage new models like GPT-5 in minutes, not months. Our value proposition isn't just speed; it's about providing a secure, reliable, and observable stack from day one, allowing developers to focus on product logic instead of operational overhead.
Why your current tech stack is probably holding you back
Adopting a new model like GPT-5 in a traditional environment involves a series of critical, yet time-consuming, steps:
- API management: Adapting API clients and managing different agentic workflows and prompt versions across your application.
- Infrastructure & deployment: Containerizing custom applications, configuring parallelized orchestration with Ray, and setting up a guardrail-enabled, multi-tier inference proxy with LiteLLM.
- Vector database integration: Ensuring your RAG pipeline's vector database (e.g., Milvus) is optimized and available for high-volume throughput and compatible with the new model's embeddings.
- Cost control & rate limiting: Leverage OpenCost for budgeting and LiteLLM for rate limiting to manage costs, enforce prioritization, create redundancy, and provide granular visibility into token usage.
- Observability & debugging: Automatic tracing, logging, prompt versioning, evaluation, and monitoring to validate the new model's performance and debug issues.
Each of these steps introduces potential points of failure and requires deep expertise, transforming a simple model upgrade into a high-stakes, multi-team project.
How Cake’s ecosystem creates a seamless workflow
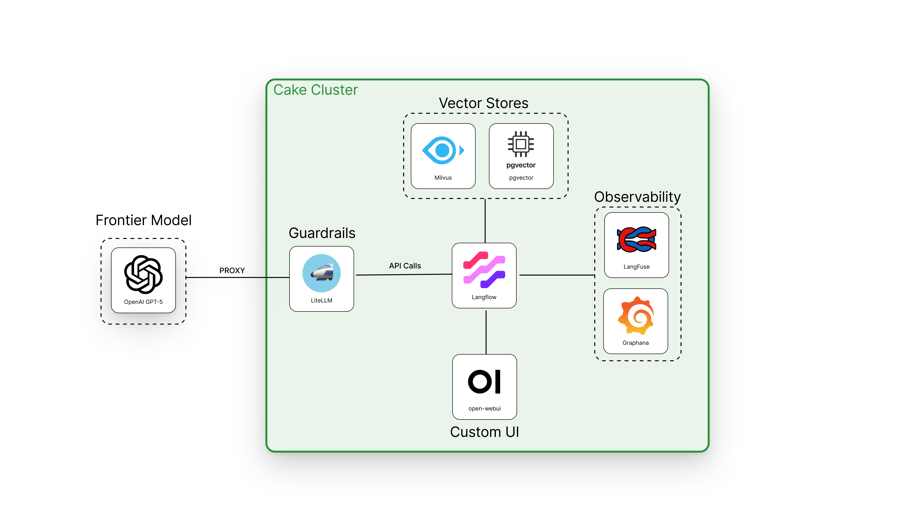
Cake abstracts away this complexity by providing a pre-integrated, open-source stack designed for agility and security. Here's how our components work together to deliver the GPT-5 advantage:
1. Unify your entire workflow with Langflow
Clients quickly prototype agentic workflows with the help of Langflow, an intuitive visual builder that allows engineers to design complex generative AI workflows as a Directed Acyclic Graph (DAG). This approach is not just for convenience; it's a powerful abstraction layer. To switch to GPT-5, a developer simply needs to update a single node in their workflow, and the change propagates seamlessly through the entire pipeline. This eliminates the need to rewrite code or manage manual integrations.

2. Seamless integration with core GenAI components
Our platform is not just a UI; it's a managed infrastructure layer. We provide pre-integrated, production-ready instances of the essential tools:
Milvus: Our managed instance of Milvus, a cloud-native vector database, is pre-configured to store and retrieve the vector embeddings of your data. The integration is seamless with Langflow, ensuring your RAG application is both fast and secure.
- Langflow: A modern age, intuitive, visual editor for agentic workflow design and orchestration, serving as the hub of AI solution architecture.
- LangFuse: Langfuse adds high-value observability and analytics to calls to models like GPT-5 by capturing detailed traces, spans, and metadata for every request. This allows you to measure latency, token usage, and cost per call, compare prompt versions, and run A/B tests across model configurations. With its OTEL-compatible traces and integration into dashboards like Grafana, Langfuse helps identify performance bottlenecks, monitor quality, and debug issues in complex LLM pipelines—turning otherwise opaque GPT-5 interactions into measurable, optimizable workflows.
3. Manage enterprise security and costs with LiteLLM
We handle the operational and financial complexities with our pre-integrated LiteLLM component. LiteLLM serves as a universal, OpenAI-compatible proxy that centralizes API key management and provides:
- Granular budgeting: Set and enforce budgets at the user, team, or project level. As GPT-5 is often more costly, this feature is critical for preventing unexpected spend during development and testing.
- Unified API access: LiteLLM provides a consistent API, allowing you to swap between different models and providers (e.g., GPT-4, Llama 3, GPT-5) without changing your application's code.
- Rate limiting & fallbacks: Configure rate limits to protect your application from excessive usage and set up intelligent fallbacks to other models if a provider's service is unavailable, as is often the case in the early days following frontier model releases.
4. Get a complete picture with Langfuse
Reliability in production requires deep visibility. Our pre-integrated Langfuse component provides an end-to-end observability layer for your LLM applications. It offers:
- Tracing & logging: Automatically traces every step of a request, from user input to final output, logging all API calls, prompts, and responses. This is invaluable for debugging model behavior.
- Evaluation & QA: Langfuse enables you to evaluate the quality of your GPT-5 outputs in a structured way, which is a key part of moving a new model from a test environment to a production release.
By managing the entire observability stack for you, Cake ensures that you can validate and deploy with confidence, without having to build a custom monitoring solution.
Meet the people behind the product
Introducing Carolyn Newmark: A leader in product innovation
A great product is more than just code and infrastructure; it’s a reflection of the people who build it. At Cake, our team is driven by a passion for solving complex problems and a commitment to the open-source community. One of the key leaders shaping our product vision is Carolyn Newmark. Her expertise in bringing new ideas to life and her dedication to helping others grow are central to how we approach innovation. We believe that the best tools are built with a deep understanding of the user's challenges, and Carolyn's approach ensures we stay focused on creating a platform that truly empowers engineering teams.
From concept to creation: A background in 0→1 product work
Carolyn specializes in what’s known as "0→1 product work"—the art and science of building brand-new products from the ground up. This involves taking a concept from a simple idea to a fully-realized, tangible product that solves a real-world problem. Her experience in this area is incredibly valuable at a company like Cake, where we are constantly exploring the frontiers of generative AI. This skill set ensures we can move quickly and effectively, turning innovative ideas into the powerful, production-ready solutions our users rely on to accelerate their own AI initiatives.
A commitment to mentorship and community building
Beyond her role at Cake, Carolyn is deeply committed to giving back to the tech community. She dedicates her time to mentoring aspiring product managers, helping individuals from all backgrounds find their footing and build successful careers in the field. This passion for fostering talent and sharing knowledge aligns perfectly with our mission. We believe that empowering individual developers and teams is the best way to drive the entire industry forward. Her work in building a stronger, more inclusive tech community is an inspiration and a core part of our company's DNA.
Why this matters
The GPT-5 announcement is more than just a new model; it's a new standard of agility. For engineering teams, the choice is clear: spend months on a fragmented, manual integration process, or leverage a platform like Cake where the core infrastructure is already in place. We empower teams to focus on delivering real value and innovative features, not on the complex and time-consuming operational work that holds them back.
Frequently Asked Questions
Why can't my team just integrate a new model like GPT-5 on our own? You absolutely can, but it's rarely as simple as just plugging into a new API. A production-ready integration requires you to configure infrastructure, manage API keys securely, set up a compatible vector database, and build systems for cost control and monitoring. Cake handles all of that foundational work for you, allowing your team to bypass weeks of operational setup and start building with the new model right away.
Your platform uses open-source tools. What's the advantage of using Cake instead of setting them up ourselves? While the components we use are open-source, making them work together seamlessly in a secure and scalable way is a significant engineering challenge. We provide these tools as a pre-integrated, managed service. This means we take on the responsibility for the complex setup, configuration, and ongoing maintenance, so your team is free to focus on creating value instead of managing infrastructure.
How does Cake help manage the higher costs associated with frontier models? We know cost is a major concern when adopting more powerful models. Our platform comes with a component that acts as a central gateway for all your API calls. This gives you the power to set and enforce strict budgets for different users or projects, implement rate limits to prevent accidental overspending, and gain clear visibility into your token usage. You get the performance without the billing surprises.
If we build on Cake, are we locked into using only GPT-5 or specific models? Not at all. In fact, our platform is designed to prevent vendor lock-in and give you more flexibility. Because we use a universal API proxy, you can easily swap between different models—like GPT-5, Llama 3, or others—often without changing your application's code. This makes it simple to test new models or switch providers based on performance, cost, or availability.
What does it mean to have "observability" for an AI application, and why is it important? Observability gives you a clear, end-to-end view into how your AI application is behaving on every single request. It automatically tracks the initial prompt, the calls made to the model, the latency, and the final output. This is essential for debugging when things go wrong, evaluating the quality of your model's responses, and identifying performance bottlenecks, turning the "black box" of an AI model into a system you can truly understand and improve.
Key Takeaways
- Integrating new AI models involves your entire stack: Adopting a frontier model like GPT-5 isn't just an API swap. It requires significant engineering effort to manage infrastructure, vector databases, cost controls, and observability, often delaying projects for months.
- A pre-integrated platform is the fastest path to production: Using a managed, open-source solution provides the essential components out of the box. This allows your team to bypass common integration headaches and deploy secure, observable AI solutions quickly.
- Shift your team's focus from operations to innovation: When the complex infrastructure is handled for you, your engineers can stop worrying about operational overhead and concentrate on building the product features that deliver real value to your users.
Related Articles
About Author

Related Post
The AI Budget Crisis You Can’t See (But Are Definitely Paying For)

Skyler Thomas & Carolyn Newmark

The Case for Smaller Models: Why Frontier AI Is Not Always the Answer
Skyler Thomas & Carolyn Newmark
The Hidden Costs Nobody Expects When Deploying AI Agents
Skyler Thomas & Carolyn Newmark

SkyPilot and Slurm: Bridge HPC and Cloud for AI

Skyler Thomas